Business Rules Extraction from Business Process Specifications Written in Natural Language


1. Introduction
A Business Rule (BR) is "a statement that defines or constrains some aspects of the business. It is intended to assert business structure or to control or influence the behavior of the business" [Business Rule Group, 2000]. BR have been recognized by many authors such as: Kilov [Kilov et al, 1997], Ross [Ross, 1997], Rosca [Rosca et al, 2002], and Kardasis [Kardasis et al, 2005], as a vital part in the system development cycle, especially in the Requirement Elicitation (RE) phase.
Although modern elicitation methods and techniques promote close interaction with stakeholders in order to identify their needs — as well as to obtain a better understanding of both problem and business — requirements engineers usually find themselves analyzing text written in natural language (NL), like interview transcripts and documented processes [Sawyer et al, 2004]. NL specifications are the inputs used by analysts in the RE phase of systems development [Achour et al, 1997].
In order to guarantee that an Information System (IS) meets business objectives, analysts have to elicit BR adequately. BR elicitation is an important part of a system development methodology, which includes the solving of difficulties such as non-determinism, incompleteness, ambiguity, and inconsistence [Rosca et al, 2002]. Specifically, completeness in BR refers to which extent all BR of a domain are identified and fully developed. Incompleteness in BR will cause an IS to fail to meet some business objectives of an organization [Rosca et al, 1997].
This research is based on the approach proposed by Martínez-Fernández [Martínez-Fernández, 2008], which uses a set of linguistic patterns and keywords. Additionally, it includes grammatical heuristics proposed by Cysneiros [Cysneiros et al, 1999 and 2000] in his conceptual model, in order to enhance completeness in the BR extraction process.
A tool for eliciting BR from process specifications written in NL has been developed, in order to completely obtain the BR of a domain. This tool includes a NL parser for working out the grammatical structure of sentences in a documented specification. The tool also includes a tgrep2-style utility for matching BR patterns from linguistic trees. Finally, this tool is supported by the set of BR heuristics, linguistic patterns, and keywords mentioned above.
This paper has been organized as follows: Section 2 reviews relevant research related to the domain of the problem. Section 3 presents the method used for improving the completeness in the BR extraction. Section 4 describes the architecture of the tool for extracting BR. Section 5 shows the tool applied to a case study. Section 6 discusses the results of this research; and Section 7 offers conclusions and future research.
2. Related Research
Two approaches have been used to extract BR from process specifications written in natural language (NL) [Bucchiarone et al, 2006]:
2.1. Linguistic Approach
In the linguistic approach, the following methods are found:
a) Methods based on syntactic and semantic analysis [Hars et al, 1996]
These methods process every sentence within a specification through a syntactic analysis component, which converts it into a syntactical tree. The syntactical tree is the input for a semantic analysis component, which will categorize every word within a sentence according to its context.
These methods identify BR in the form of action/consequence (IF/THEN) from the syntactic and semantic information of every sentence. BR identification is carried out through the automatic search of the if/then form in every sentence.
These methods require little human intervention. On the other hand, they are only capable of extracting business rules in the form of action/consequence (IF-THEN); for that reason, they miss all BR that appear in a different manner. In order to improve these methods, it is necessary to bear in mind different BR forms and add them to these methods.
b) Methods based on grammatical heuristics [Leonardi et al, 1998 and 2001; Cysneiros et al, 1999 and 2000]
These methods suggest a set of grammatical heuristics, which can be used as guides by requirements engineers in the BR extraction from specifications of business processes written in NL. This approach incorporates BR into a structure, which contains sentences about the desired system and written in natural language according to defined patterns. The incorporation of BR is carried out through a LEL (Lexicon Extended of Language). LEL is a meta-model designed to help in identifying the vocabulary used in the macrosystem.
These methods can be improved by reducing the human intervention in the BR extraction process, as well as by adding the linguistic patterns and keywords suggested in the SBVR (Semantics of Business Vocabulary and Business Rules) specification [Object Management Group, 2008] and the RuleSpeak language [Ross et al, 2001].
c) Methods based on linguistic analysis and linguistic patterns [Mart�nez-Fern�ndez, 2008]
Initially, these methods obtain the morphologic, semantic, and syntactic information about the process specification written in natural language through a linguistic analysis tool. The previous analysis generates a linguistic tree for every sentence within the process specification. The product of the linguistic analysis is the input to a component for detecting BR, which will match a BR pattern in linguistic trees. The component to detect a BR is composed of a set of linguistic patterns and keywords. These linguistic patterns and keywords are taken from the SBVR specification [Object Management Group, 2008] and the RuleSpeak language [Ross et al, 2001]. Finally, matched sentences are taken by analysts who will decide which of them are BR.
These methods can be improved by adding some grammatical heuristics proposed by Cysneiros [Cysneiros et al, 1999 and 2000] as well as by using a more accurate and reliable component for BR detection.
2.2. Statistical approach
In the statistical approach, the following method is found:
a) Methods based on statistic natural language processing [Sawyer et al, 2004]
These methods compare a process specification against a corpus of text, in order to obtain word frequency. The words with higher frequency will be tagged as keys candidates. A semantic and a syntactic analysis component is used to structure the text, to eliminate lexical ambiguity, to find lexical affinities among keys candidates, and to contextualize them inside the process specification. Analysts identify BR in the process specification based on the information obtained through the method.
The processes of the contextualization of keys candidates and identification of BR fall to analysts. For this reason, the extraction's success depends on the analysts' abilities. In order to improve these methods, it is necessary to reduce human intervention.
3. Method for Improving the Completeness in BR Extraction
We now take a closer look at the method used for improving the completeness in the BR extraction. BR extraction from a process specification written in natural language is composed by two main activities: linguistic analysis and detection of BR, as shown in Figure 1.
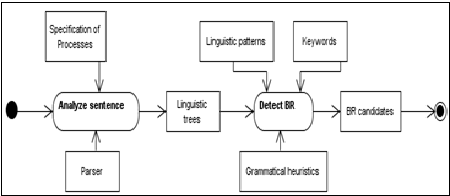
Figure 1. BR extraction process
Linguistic analysis obtains morphologic, semantic, and syntactic information of every sentence within a process specification. The product of this process is a linguistic tree of every sentence, which contains relevant information about the structure and meaning of each sentence.
Linguistic trees are the inputs to the BR detection activity. BR detection finds the presence of linguistic patterns, grammatical heuristics, and keywords in linguistic trees provided by the linguistic analysis.
BR detection is supported by a set of linguistic patterns and keywords used by Martínez-Fernández [Martínez-Fernández, 2008], which have been proposed by both the SBVR (Semantic of Business Vocabulary and Business Rules) specification [Object Management Group, 2008] and the RuleSpeak language [Ross et al, 2001].
The SBVR is an adopted standard of the Object Management Group (OMG), which is intended to formalize complex compliance rules, such as operational rules for an enterprise, security police, standard compliance, or regulatory compliance rules. This specification supplies a set of English structures and common words to provide a simple and straightforward mapping to SBVR concepts [Object Management Group, 2008]. A small fragment of English structures and common words is shown in Table 1 (where p and q represent expressions of propositions).
Structure |
Description |
each |
universal quantification |
at least one |
existential quantification |
if p then q |
implication |
... must ... |
obligation formulation |
never |
necessity formulation |
neither p nor q |
nor formula |
The RuleSpeak language provides a set of sentence patterns, which is a basic structure to express a certain type of rule in a consistent, well-organized manner. The purpose of a sentence pattern is to ensure that written rules are more readily understood and to ensure that different analysts working on a large list of rules express the same ideas in the same ways [Ross et al, 2001]. Some examples of sentence patterns suggested by the RuleSpeak language are shown in Table 2.
may … only if |
must be computed as |
must be considered … if |
Before | During | After |
In addition to the above linguistic patterns and keywords, this research includes the grammatical heuristics proposed by Cysneiros [Cysneiros et al, 1999 and 2000], which were created to help the requirements engineers in the process of eliciting business rules. Some examples of these heuristics are shown in Table 3.
When + phrase + then/implies + phrase |
Subject + will + verbal phrase |
… cannot … |
If + phrase + then/implies + phrase |
4. Tool Architecture
BRElicitationTool is a tool for automatic extraction of business rules from a process specification written in natural language. This tool has been developed in order to reduce incompleteness in the BR elicitation process. BRElicitationTool development was carried out as follows:
The main activities depicted in Section 3 can be performed by reusing software components or applications. In order to execute the linguistic analysis and the BR detection in a reliable and an efficient manner, it is necessary to evaluate specialized components available in academic and scientific environments.
4.1. Linguistic Analysis
For the linguistic analysis, there are plenty of components and tools (called parsers) in the academic and scientific community, which can be used. A set of these components was selected and they were qualitatively evaluated under precision and recall metrics [Harmain et al, 2000] and under a measure of its capabilities. (This measure refers to the additional functionalities of every parser, e.g., POS Tagging, Named Entity Recognizer, and detection of patterns in linguistic trees, among others. This measure goes from 1 to 5). This qualitative evaluation yielded the results shown in Table 4.
Parser |
Recall |
Precision |
Capabilities |
Link [Maarneffe et al, 2006] |
Medium |
— |
1 |
Stanford [Sagae et al, 2008] |
High |
High |
5 |
Charniak [Swanson et al, 2006] |
High |
High |
— |
Enju HSPG [Sagae et al, 2008] |
High |
High |
3 |
FreeLing [Atserias et al, 2006] |
High |
— |
4 |
TreeTagger [Allauzen et al, 2008] |
High |
High |
2 |
RASP [Sagae et al, 2008] |
Medium |
Medium |
3 |
Charniak & Jhonson [Sagae et al, 2008] |
High |
High |
— |
As shown in Table 4, the Stanford parser is the selected component for the linguistic analysis. When a sentence within a process specification is passed through the Stanford parser, it produces a linguistic tree, as shown in Figure 2.
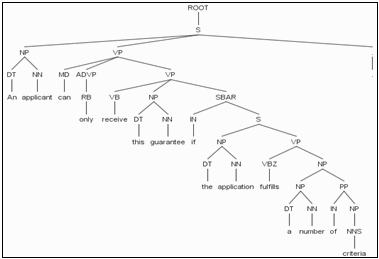
Figure 2. Linguistic tree for the sentence: "An applicant can only apply to receive this guarantee if the applicant fulfills a number of criteria."
4.2. BR Detection
In contrast to the parser selection, there are few components for this specific activity and some of them were their own implementations. For this reason, this research took advantage of the Tregex utility developed by The Stanford Natural Language Processing Group, which is based on the tgrep2-style utility for matching BR patterns in trees. This component guarantees reliability because it has been specifically developed for the linguistic trees provided by the Stanford parser. When the linguistic tree in Figure 2 is passed through the component for detecting BR along with a set of BR linguistic patterns, it recognizes the following pattern: "NP… can only … VB ... if… NP", as shown in Figure 3. The presence of a BR linguistic pattern in a sentence makes it candidate for being a BR.
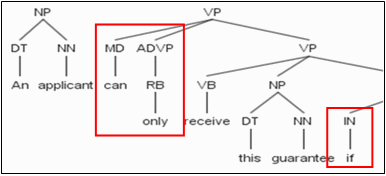
Figure 3. Linguistic patterns identified in a sentence
The tool for automatic extraction of BR, called BRElicitationTool, integrates these components in its architecture, in order to enhance the completeness of the BR. Figure 4 shows the tool component diagram.
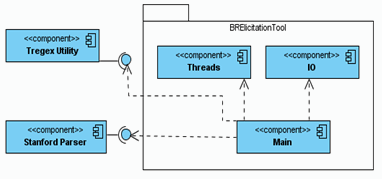
Figure 4. BRElicitationTool component diagram
5. Case Study
In order to evaluate the method described in Section 3 through the BRElicitationTool, a fragment of the process specification in the case study [Weiden, 2000] has been chosen. The domain of this case study is "The SHARING Project," which aims to develop an Information System dealing with mortgages for the entire ING organization in the Netherlands.
BRElicitationTool can process an entire documented specification as well as individual sentences. When an entire specification is analyzed, the tool generates a document with all the BR candidates' sentences. When a specific sentence is analyzed, the tool suggests the presence of a BR and shows the BR linguistic pattern detected, as shown in Figure 5 with the sentence: "It must also take into account and preserve the difference between the labels." The BRElicitationTool detects the presence of the patterns "NP … and … NP" and "NP|WDT … must … VB" in the sentence.
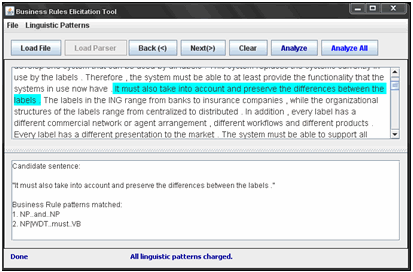
Figure 5. BRElicitationTool analysis for: "It must also take into account and preserve the difference."
In order to evaluate completeness of the method depicted in Section 3 through the tool, the following hypothesis was stated:
Ho: Automatic extraction of BR yields results in fewer missed BR than manual extraction.
In order to validate this hypothesis, the following experiment was performed: one group of 33 computer science engineering students and teachers identified BR in the case study without any help of a software tool. Additionally, the BRElicitationTool automatically identified BR in the case study. With the previous results, along with the BR identified by the case study authors, precision and recall metrics [Harmain et al, 2000] were calculated as shown in Table 5.
Source (BR patterns) |
Recall |
Precision |
Analysts |
28.42% |
68.44% |
BRElicitationTool (SBVR & RuleSpeak) |
72.97% |
71.05% |
Where,
• Recall: It reflects the completeness of the results produced by the tool or by the analysts [Harmain et al, 2000].
Recall = Ncorrect / Nkey
• Precision: It reflects the accuracy of the tool or analysts as well (i.e., how much of the information produced by the tool or by the analysts was correct) [Harmain et al, 2000].
Precision = Ncorrect / (Ncorrect + Nincorrect)
Where,
• Ncorrect refers to the number of correct BR identified by the tool or by the analysts;
• Nkey refers to the number of BR identified by the case study authors, and
• Nincorrect refers to the incorrect BR identified by the tool or by the analysts.
In order to enhance the completeness obtained by the SBVR specification [Object Management Group, 2008] and the RuleSpeak language [Ross et al, 2001], grammatical heuristics proposed by Cysneiros [Cysneiros et al, 1999 and 2000] were included to the set of BR patterns in the BRElicitationTool, with the results shown in Table 6.
Source (BR patterns) |
Recall |
Precision |
BRElicitationTool (SBVR & RuleSpeak) |
72.97% |
71.05% |
BRElicitationTool (Cysneiros) |
56.76% |
58.33% |
BRElicitationTool (SBVR & RuleSpeak & Cysneiros) |
89.19% |
66.00% |
6. Results Analysis
Based on the results shown in Table 5, the value of the recall metrics for the BRElicitationTool (72.97%) is considerably greater than the value for the group of analysts (28.42%). For this reason, hypothesis Ho is accepted; therefore, automatic extraction of BR (BRElicitationTool for this case) yields results with fewer missed BR than manual extraction.
The results shown in Table 6 reflect the enhancement achieved by blending both the linguistic patterns and keywords suggested by the SBVR specification and the RuleSpeak language with the grammatical heuristics proposed by Cysneiros. Including Cysneiros' heuristics increases the value for the recall metrics by 22% approximately (for this case study); therefore, it has been demonstrated that the combined use of the BR linguistic patterns and keywords proposed by these three sources in a BR extraction process yields results with fewer missed BR than every approach on its own.
On the other hand, the values for the precision metrics for all the forms of the proof are not promising because its greatest value was 71.05% for BRElicitationTool (with SBVR & RuleSpeak patterns). Generally, these values depend on some of the keywords suggested by the method, because there are keywords or patterns that can be seen in non-BR sentences, like: "NP … and … NP" and "NP … have|be … NP" (among others).
7. Conclusions and future research
Despite the initiative of different approaches for a close interaction with stakeholders, requirements engineers usually find themselves analyzing text manually for extracting BR of a System under Discussion [Sawyer et al, 2004], which leads to a decrease in the completeness of the identified BR. This paper has presented BRElicitationTool, a tool for the automatic extraction of BR from process specifications written in natural language, which is based on the approach proposed by Martínez-Fernández [Martínez-Fernández, 2008] as well as the conceptual model proposed by Cysneiros [Cysneiros et al, 1999 and 2000].
This research demonstrated that automatic extraction of BR yields results with fewer missed BR than manual extraction. It has found that automatic extraction of BR through linguistic analysis and patterns detection is a promising method for identifying BR of an organization. Additionally, this research has demonstrated that combining the linguistic patterns and keywords suggested by both the SBVR specification [Object Management Group, 2008] and the RuleSpeak language [Ross et al, 2001] with the grammatical heuristics proposed by Cysneiros [Cysneiros et al, 1999 and 2000] yields more complete results than each of these approaches on its own.
In future research, the authors propose the enhancement of precision obtained in automatic extraction of BR from business process specifications written in natural language. Additionally, the use of specific ontologies in order to improve the completeness obtained in BR extraction is also proposed.
References
Achour, C. and Rolland, C. (1997), Introducing genericity and modularity of textual scenario interpretation in the context of requirements engineering. Technical Report, Centre de Recherche en Informatique, Université de Paris 1, Paris. In: CREWS Technical Report No. 21.903.
Allauzen, A. and Bonneau-Maynard, H. (2008), Training and evaluating of POS taggers on French MULTITAG Corpus. In: Proceeding of the LREC '08.
Atserias, J., Casas, B., Comelles, E., González, M., Padró, L. and Padró, M. (2006), FreeLing 1.3: Syntactic and semantic services in an open-source NLP library. In: Proceeding of the 5th LREC.
Bucchiarone, A., Gnesi, S., Lami, G., Berry, D. and Trentanni, G. (2006) A New Quality Model for Natural Language Requirements Specifications. In: Proc. Of the 12th International Working Conference on Requirements Engineering: Foundation for Software Quality.
Business Rules Group. (2002) Defining Business Rules ~ What Are They Really? Guide Business Rules Project, Final Report. Revision 1.3.
Cysneiros, L., Macedo-Soares, T. and Leite, J. (1999), Using 9001 to Elicit Business Rules. Proc. of 4o IEEE International Software Engineering Standards Symposium - Brazil.
Cysneiros, L. and Leite, J. (2000), Eliciting Business Rules through ISO 9000 Documentation: a Domain Oriented Conceptual Model. Proc. of the 3rd Workshop Ibero-Americao em Engenharia de Requisitos e Ambientes de Software – Cancun.
Harmain, H. and Gaizauskas, R. (2000), CM-Builder: An Automated NL-based CASE Tool. In: Proceedings of the fifteenth IEEE International Conference on Automated Software Engineering (ASE '00), Grenoble.
Hars, A. and Marchewka, J. (1996) Eliciting and Mapping Business Rules to IS Design: Introducing a Natural Language CASE Tool. In: Proceedings of Decision Science Institute.
Kardasis, P. and Loucopoulus, P. (2005), A roadmap for the elicitation of business rules in information systems projects. Business Process Management Journal, Vol. 11 No. 5.
Kilov, H. and Simmonds, I. (1997), Business rules: From business specification to design. Technical Report RC 20754, IBM TJ Watson.
Leonardi, C., Leite, J. and Rossi G. (1998), Estrategias para la identificación de Reglas de Negocio. Anais de Sbes98 "Simposio Brasilero de Engenharia de Software" Sociedade Brasilera de Computacao, Maringa, Brasil.
Leonardi, C. (2001), Una estrategia de modelado conceptual de objetos basada Modelos de Requisitos en Lenguaje Natural. Facultad de Informática – Universidad de la Plata - Argentina.
Maarneffe, M., MacCartney, B. and Manning, C. (2006), Generating Typed Dependency Parses from Phrases Structure Parses. In: Proceeding of the 5th LREC.
Martínez-Fernández, J., González, J., Villena, J. and Martínez, P. (2008), A Preliminary Approach to the Automatic Extraction of Business Rules from Unrestricted Text in the Banking Industry. Lecture Notes in Computer Science, NL and IS.
Object Management Group (OMG). (2008), Semantics of Business Vocabulary and Business Rules (SBVR). Formal Specification, Version 1.0.
Rosca, D., Wild, C., Greenspan, S. and Feblowitz, M. (1997), A Decision Making Methodology in Support of the Business Rules Lifecycle. Old Dominion University.
Rosca, D. and Wild, C. (2002), Towards a flexible deployment of business rules. Experts systems with applications, Vol. 23.
Ross, R. (1997), The business rule book: classifying, defining and modeling rules. Data Base Newsletter.
Ross, R. and Lam, G. (2001), RuleSpeakTM Sentence Templates: Developing Rule Statements Using Sentence Patterns. Business Rules Solutions, LLC. DataToKnowledge Newsletter.
Sagae, K., Miyao, Y. and Tsujii, J. (2008), Challenges in Mapping of Syntactic Representations for Framework-Independent Parser Evaluation. In: Proceedings of the Workshop on Automated Syntactic Annotations for Interoperable Languages Resources at the First ICGL.
Sawyer, P. and Cosh, K. (2004), Supporting MEASUR-driven analysis using NLP tools. In: 10th International Workshop on Requirements Engineering.
Swanson, R. and Gordon, A. (2006), A Comparison of Alternative Parse Tree Paths Labeling Semantic Roles. In: Proceedings of the COLING/ACL.
Weiden, M. (2000), A Critique of the Pure Business-Rule Approach. M.Sc. Thesis, University of Amsterdam. Department of Social Science Informatics.# # #
Standard citation for this article:
About our Contributor(s):











Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.