Data Mining and the Use of Data to Find and Improve Rules

Last month I introduced the idea of decisions in the context of what we call Enterprise Decision Management. Remember,
Enterprise Decision Management is an approach for automating and improving high-volume operational decisions. Focusing on operational decisions, it develops decision services using business rules to automate those decisions, adds analytic insight to these services using predictive analytics, and allows for the ongoing improvements of decision-making through adaptive control and optimization.
Having found the decisions you think might be suitable for the approach, the next step is typically to lay out and then define the business rules that support that decision. Mining business rules from code, reviewing regulations and policy manuals, interviewing experts, and many other techniques can be used to find the rules that support your decision. Given this column is on the Business Rules Community, it does not seem worth repeating all the great advice that is already available on the BRC about rules in general. What I will focus on, however, is the less common approach of using data to find and refine business rules.
The first way to use data to improve and refine business rules is simply to analyze and inspect the historical data you have. If you are writing rules about eligibility of customers for particular products, get hold of the data that showed who was sold which product in the past. While this data will probably not be complete — only products actually purchased (presumably one of the products for which the customer was eligible) rather than all the products they could have purchased for example — it may well provide useful clues. For instance, if no-one can be sure of the minimum or maximum allowed for a particular attribute then the data will at least give you a range of acceptable values. If no customer with less than 12 months on the books has ever been sold product X then perhaps this is meant to be a rule, for instance.
It is also often the case that rules are intended to divide instances, of customers say, into groups that will then be treated differently. For instance, rules might be written to cream off the "best" customers and make them different offers. Straightforward analysis of the historical data can be used to see what percentage of current customers would be covered by those rules, helping to ensure that you get the kind of distribution for which you were hoping. Experimenting with this analysis may help refine sensible and useful cut-offs and other values in the rules you write.
So far this is really just using data to understand the implications, or confirm the consequences of business rules. It is possible to go beyond this, however, and use data mining to discover the rules you should be using. A classic example is in customer segmentation. Implementing customer segmentation in business rules is very straightforward — even quite complex segmentation schemes can be represented by a reasonable collection of rules especially if you can use a decision tree. In a decision tree, the end of each branch represents a specific outcome (assignment to a segment, say) and each branching point is a condition. The illustration shows a simple example — a set of 5 rules and a completely equivalent decision tree.
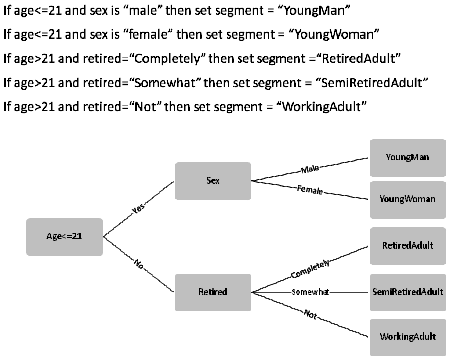
You can develop this kind of decision tree by hand — judgmentally — but if you have a lot of information about your customers (and you probably do) then data mining is likely to be much more effective. Using data mining techniques such as CART (Classification and Regression Trees) or CHAID (CHi-squared Automatic Interaction Detector) you can derive decision trees — rulesets — that are statistically significant. If you want to know what segmentation rules will divide your customers into those likely to remain customers, those who are almost certain to leave without renewing, and those in between, these techniques can help you find the attributes you need to test and the exact values that you need. Your rules go from being judgmental to being analytically derived — mined from the historical data that you have and based on what has really worked in the past not just what you think worked in the past.
Using data in these ways and others to validate, refine, or mine your business rules is a great way to put your data to work in the rules-based decisions you are building. There is a lot of information on this in Smart (Enough) Systems, and don't forget you can use RSS or e-mail to subscribe to the Smart (enough) Systems blog. Next time, moving to predictive analytics in decision management.# # #
Standard citation for this article:
About our Contributor:











Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.