Adaptive Control, Champion/Challenger, and Decision Management

Last month I discussed predictive analytics in decision management. This month I will talk about adaptive control and its role in continuous improvement of decision making. Recapping,
Enterprise Decision Management is an approach for automating and improving high-volume operational decisions. Focusing on operational decisions, it develops decision services using business rules to automate those decisions, adds analytic insight to these services using predictive analytics, and allows for the ongoing improvements of decision-making through adaptive control and optimization.
Let's start by continuing with the scenario I used last month — customer retention. We have already discussed how being able to make predictions from past behavior can improve offers. But let's assume I make a change to my offer rules based on the analytics and apply that change to everyone. Now I have two problems:
- I will not be able to compare my new offer with my old one.
Sure, I can compare the results I am getting now with the ones I used to get in the past, but changes may be a result of a different economic climate, for instance, rather than thanks to a better offer.
- I may not know the results of the retention offer for some time.
If I start making retention offers some months before a current contract expires — which is the right way to do this so that my customers don't already have an alternative before I try to retain them — then it may be months before I know how successful I was. Only once the renewal date is past for a customer who was at risk will I be able to see who actually renewed. Even then I may not know who might have renewed anyway — predictive analytics are just probabilities after all. Just because someone was likely not to renew (and so got a retention offer) does not mean they would not have renewed, only that they were unlikely to.
Finally, just to maximize the complexity of this problem, I should really consider how good a customer someone is over time to see if it was actually worth the cost of retaining them!
Figure 1 shows one way to consider this. Any given customer has a current profitability trajectory or prediction. Today I could take one of several actions — different retention offers in our example — or do nothing. Each action, and doing nothing, results in a different profitability trajectory shown with the Action A, Action B, and Action C paths. When we make the decision we don't know what these paths will look like — they are in the future — but we want to pick the most profitable action for each customer when we make the decision.
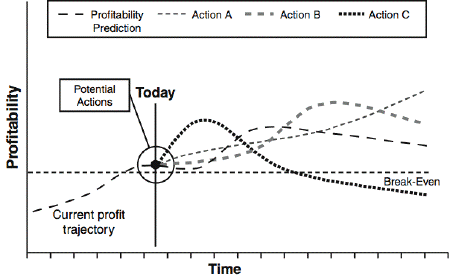
Figure 1. Actions influence probability in different ways.
Reproduced from Smart (Enough) Systems, Taylor and Raden, 2007.
At first sight this may seem impossible — how can we know the future outcomes of our actions? Well, we can't.
Fortunately, for those of us building information systems, there is a continuous stream of customers reaching any given decision point. If we have a set or cohort of customers reaching the "renewal offer decision point" today then we will also have some more next week, and the next and so on. This allows us, if we approach the problem correctly, to use the results of our decisions for the first cohort to improve how we treat the next cohort and to continuously improve our results as a consequence. This is adaptive control.
The basic approach works like this:
- At a decision point, make it possible to assign customers to one of several decisions.
Instead of assuming that each time a customer reaches a decision point a single set of rules and analytics will be executed, make it possible to assign a customer to one of several different decision approaches.
- For each such decision, design not one but many approaches.
Instead of defining just one set of rules and analytics for each decision, think about alternative approaches. Perhaps there is a set of rules that represents a conservative but cheap retention strategy, and another that is more aggressive and expensive.
- Identify one approach as a Champion.
This is your default approach. It might be your current approach, or it might simply be the one you have most confidence in or even the cheapest. The remaining approaches will be Challengers.
- At the decision point, assign most customers to the Champion and randomly assign the others to Challengers.
Most customers — 90% or even more — will get the Champion approach applied to the decision when they reach the decision point. The remainder will be randomly assigned one of the other approaches.
- Track the results.
You must be able to see which approach was used for each customer, and you must establish a mechanism to report on the success of each. Measuring various KPIs for each segment of the population (Champion, Challenger 1, Challenger 2, etc.) will let you see which works best.
- Reassess Champion.
After a period suitable for measuring results has passed, see if any of the Challengers are outperforming the Champion. If one is, then make that approach the new Champion (meaning that most customers reaching the decision point in the future will use it).
- Design and implement new Challengers
Regardless of whether the Champion has changed, retire the unsuccessful Challengers and design some new ones. Put these into production so that some of the customers reaching the decision point are acted on by these new approaches.
- Continue to test and refine.
The net result of this is that you always have a Champion approach — the approach that you believe to be the best — being applied to almost all customers, while some potentially effective Challengers are used with some customers so you can see if they are, in fact, preferable. Constant testing, continuous improvement.
Now I am just scratching the surface in this article — there is a whole art and science to adaptive control, experimental design, and randomized testing — but hopefully I have given you a feel for why it matters in decision management and how to get started. Don't forget that there is a lot more information on this in Smart (Enough) Systems, and you can use RSS or e-mail to subscribe to the Smart (enough) Systems blog.# # #
Standard citation for this article:
About our Contributor:










Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.