About Use Cases

The latest hot topic in the information systems marketplace is "use cases." These are models of the interaction between a prospective system and the users ("actors") of that system. The UML has a graphic for describing them, and they are touted as the optimal way to determine requirements for new systems. There is, however, considerably less than meets the eye. This column will discuss that.
Some History
In the 1970's your author spent a lot of time interviewing business people to try to determine what they wanted from new information systems. For the most part, the answers to his questions were such illuminating things as "Make the current system work better (faster, more easily, etc.)," "Make my job easier," or "Make the data entry (via punched cards) faster."
The modeling tool of choice in those days was the data flow diagram, created simultaneously (with slightly different notations) by Tom DeMarco[1] and a married couple, Chris Gane and Trish Sarson.[2] These diagrams, laboriously created, showed the information processing activities of a company, linked by flows of data from one to the other. They also showed "data stores" -- where data would stop momentarily in its travels around the company -- and "external entities" -- the people and other entities in the world that were the ultimate source and destination of all data. This technique provided a rigorous means for describing both the current physical mechanisms for moving data around, and also the underlying ("logical") functions that were being achieved by all that data movement.
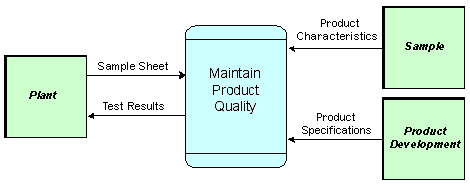
Figure 1. A "Context" Data Flow Diagram
In addition to providing the ability to show data flows at a particular level of detail, the technique also provided a formal way of "exploding" activities, to show their component activities. The process would begin with a "context data flow diagram" showing a single process for the company as a whole (or some major part of it), and all the external entities that interacted with it (see Figure 1). This would then be exploded into the primary functions that comprised it (see Figure 2). Each of these could be exploded in turn, and so on, until the entire company was described in detail.
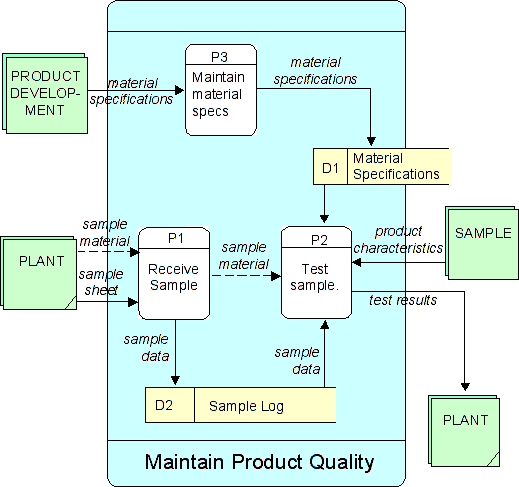
Figure 2. An "Exploded" Data Flow Diagram
These interviews and this modeling tool were then used as the basis for developing requirements for new systems. Invariably, one or both of two things happened:
- We brought in completely new technology that made the business people's expression
of "requirements" irrelevant, or
- We built exactly what they asked for and they discovered either that their business
had changed so they needed something completely different, or that they hadn't really
understood the question and what it was they really wanted.
As an industry, we were never able to keep up with demand.
Insight
In 1970, E. F. Codd presented his relational model to interested academics.[3] At the same time, IBM and other companies began to recognize that there was a market for "data base management systems" which organized system development efforts around data structure more than process. In the mid-1970's, Peter Chen invented the first data modeling technique.[4] Subsequently, Clive Finkelstein and James Martin developed Information Engineering -- an approach to the entire process of requirements analysis and systems development that emphasized data (and specifically, data modeling) as well.[5]
This whole data idea was slow to catch on initially, but the seeds were planted. By the early 1980's, data in general and the relational model in particular began to get noticed. Gradually, it became apparent to more and more people that if we would look at data instead of process in our requirements gathering, a couple of very salutary things would happen:
- It was a lot less work to understand the underlying nature of the company than
it had been to understand its processes in the necessary detail.
- The systems we built based on data orientation were much more robust and flexible
than systems based on a process orientation.
Data modeling, relational data base management systems, and data administration all became meaningful and popular. Computer systems began to be designed around the structure of the things of significance to the corporation and the relationships among them.
Enter Object Orientation
In the 1960's real-time systems began to be developed using an approach called "object-oriented" programming. In this, it was recognized that such real-time systems were primarily concerned with "things" (objects) and that program code was really there to support these things. The techniques went public with the arrival of windows-based systems in the early 1980's, with their need to program cursors, windows, and the other objects that are manipulated in a windows-based environment.
By the late 1980's the object-oriented community discovered commercial applications and the need for effective requirements analysis to support these kinds of applications. The object-oriented idea was applied to analysis, effectively commandeering the data-oriented techniques that had been popular in the business analysis world up to that point. Data-oriented requirements analysis was renamed "object-oriented analysis."
Enter Use Cases
One of the proponents of the object-oriented approach to analysis was Ivar Jacobson, who had previously developed a technique for describing the interaction between people and systems called "use cases."[6] Because of Mr. Jacobson's prominence in the object-oriented community, the technique was christened as an "object-oriented" technique, and it was made part of the UML ("Unified Modeling Language"). As Mr. Jacobson puts it, "The use case model will control the formation of all other models."[7]
However . . .
There are some problems with use cases. Yes, they are appropriate to describe the interaction of a prospective system with its users, but they are graphically not as rich as data flow diagrams (see Figure 3).

Figure 3. A Use Case Diagram
As diagrams, a use case is very much like context data flow diagrams, although in some cases, a collection of use cases may be shown -- analogous to one level down from a context data flow diagram. The squares that were used for external entities have been replaced with stick figures for the "actors" in use cases, and the round-cornered rectangles or circles have been replaced with ellipses.
The difference is that, unlike data flow diagrams, they don't:
- Document the data flows.
- Provide a formal structure for exploding large processes into small ones.
You can describe the data processed by the use case in the text accompanying it, but normally even that is not at the detail of the flows in and out. You can describe the steps that constitute a use case in the accompanying text, and you can "include" in the diagram a reference to other use cases that are common to multiple parent use cases, but there is no formal explosion process. Often, not all component processes are shown.
This hardly makes it a powerful modeling technique. In other words, both data flow information and the steps that comprise a process must be captured in the textual documentation of a use case. Use cases turn out to be only really effective as a vehicle for organizing textual descriptions.[8]
The Serious Problem
Whatever the use case's graphic shortcomings, there is a more serious problem with it. Specifically, creating a use case presumes that the decision has already been made as to what system is to be built.
When used as a technique for determining system requirements, use cases revert back to the old approach of asking a business person to examine his processes and speculate as to how a new automated system might change them. We have returned to the 1970's and its process-oriented approach to developing systems.
As Mr. Jacobson puts it, a domain object model (for example) consists of "objects that have a direct counterpart in the problem domain under consideration, and serve to support for the development of the requirements model."[9] In other words, start with the use case requirements model, and then just do an object (data) model of the objects identified in the use case.
This is completely counter to the idea that has been developing for the last twenty years that you start by using function and data models to understand the nature of your business, before you try to decide what to automate and how.
Suppose you are working for a large travel agency that produces airline tickets for corporate clients. This agency has the idea that ticket printers can be installed in each client site, so the client would then be able to print out his own tickets. You laboriously produce use cases describing the interaction of the typical client with this ticket-producing machine. These use cases are then the basis for a major development and implementation effort in dozens of clients' offices around the city.
Then, a month after the system is installed, Continental Air Lines announces that it will now be issuing "e-tickets." Paper tickets are no longer necessary at all.
The "ticket" object identified in the travel agency's use cases was significantly different from the "passenger access" object that was finally implemented by the airline.
Value of use cases
Yes, use cases can be valuable. If you meet the following conditions:
- You have done a data model and understand the true structure of a company's information;
- You have identified the true functions the company is chartered to carry out;
- You have come to understand:
- the true gaps between the data required by the company and the data available,
and
- the true gaps between the functions of the company and the current processes trying to carry out those functions.
- the true gaps between the data required by the company and the data available,
and
If you have done all of these things and concluded that a new system is appropriate that performs specific functions, only then is it appropriate to sit down and speculate as to how people might use such a system.
The use case idea is very valuable in analyzing the structure of the user interface of a prospective system.
But that is all it is. It is not an appropriate vehicle for determining what systems are required in the first place.
References
[1] DeMarco, Thomas. Structured Analysis and System
Specification. Englewood Cliffs, NJ: Prentice-Hall, 1978. ![]()
[2] Gane, Chris, and Trish Sarson. Structured Systems
Analysis: Tools and Techniques. Englewood Cliffs, NJ: Prentice Hall, 1979. ![]()
[3] Codd, E. F. �A Relational Model of Data for Large
Shared Data Banks,�. Communications of the ACM, Vol. 13, No. 6 (June 1970).
![]()
[4] Chen, Peter. �The Entity-Relationship Approach to
Logical Data Base Design�. The Q.E.D. Monograph Series: Data Management. Wellesley,
MA: Q.E.D. Information Sciences, Inc., 1976-1977. This is based on his articles:
�The Entity-Relationship Model: Towards a Unified View of Data,� ACM Transactions
on Database Systems, Vol. 1, No 1, (March 1976), pages 9-36, and �The Entity-Relationship
Model: A Basis for the Enterprise View of Data,� AFIPS Conference Proceedings,
Vol. 46, AFIPS Press, N.J., (1977 National Computer Conference), pages 77-84. ![]()
[5] The original paper was published by the two authors
in the early 1980s. Mr. Finkelstein published the method later as: Finkelstein, Clive.
An Introduction to Information Engineering : From Strategic Planning to Information
Systems. Sydney: Addison-Wesley, 1989. ![]()
[6] Jacobson, Ivar. Object-Oriented Software Engineering:
A Use Case Driven Approach. Reading, MA: Addison-Wesley. 1992. ![]()
[8] Cockburn, Alistair. Writing Effective Use Cases.
Reading, MA: Addison Wesley, 2000. ![]()
[9] Jacobson, Ivar. op. cit., p. 129. ![]()
# # #
Standard citation for this article:
About our Contributor:

")








Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.