The Role of Reference Data in Business Rules

Interest in business rules has always been closely linked to the disciplines of data management and database design. This is not simply a reflection of the background of many of the IT professionals who are actively involved in business rule projects. Rather it is a result of the realization that the "logic" of business rules must operate on data stored in databases. For instance, a business rule that performs a calculation will most likely obtain input data values from a database and then store the result there.
While interactions of this kind with "regular data" are interesting, the way in which "meta data" is linked to the logic of rules is of much greater significance. There is no doubt that business rule logic can very often be expressed as meta data stored in a database. This is attractive because it permits other meta data --- perhaps describing definitions, ownership, or issues -- to be defined in tables related to those holding business rule definitions.
Anyone who tries to do this will soon find that they are designing a database (perhaps called a repository) that looks quite different from the database containing the data that the rules operate on -- with one exception. This exception is "reference data," which exists in the data the rules operate on and is used within the logic of the rules themselves. This article looks at what makes up this rather special category of data, just why it is important in business rules, and what an enterprise must do to manage it in order to have an effective business rules strategy.
Meta Data vs. Reference Data
"Meta data" is usually defined as "data about data," which is not very illuminating and glosses over a lot of complexities. In addition, "meta data" is often used to cover a rather large area and many different kinds of data. For instance, it is often used simply to distinguish data that defines the logic of a business rule from data on which the business rule operates.
All of this leads to a rather superficial view, not only of meta data but also of data architecture in general. It ignores the fact that an enterprise's data has a definite large-scale structure that can be differentiated into a number of layers, of which meta data is only one.
Reference data is another of these layers. It is quite distinct from meta data and plays a particularly important role in the formulation of business rules. Unfortunately, even though many data professionals are aware of its existence it is often ignored, and this in turn has an adverse impact on a general understanding of business rules.
Reference data is often called "code tables" or "lookup tables" in the IT world. These are familiar small tables that often consist of just a primary key "code" attribute and a single non-key attribute that holds a name or description. Examples include things like Country, Currency, SIC Classification, Account Status, and Customer Type. The structural simplicity of these tables is misleading and is probably the reason why "reference data" gets such little attention.
A formal definition of reference data is:
| Reference data is any kind of data that is used solely to categorize other data found in a database, or solely for relating data in a database to information beyond the boundaries of the enterprise. |
It is obvious that reference data exists as actual implemented data values in a database, and so it cannot be mistaken for meta data, which describes other data in some way. However, in terms of importance it comes close to meta data since reference data is often used as reporting dimensions, and its unique role in categorizing other data means that it enters into play within the logic of business rules.
As a class of data, reference data is actually quite diverse. It is important to appreciate this diversity in order to better understand the general role of reference data in business rule logic. The major types of reference data are as follows:
- Things external to the enterprise. Examples are country, currency,
and credit rating. Very few enterprises in the business of producing new countries,
currencies, etc., but all enterprises need to put their information into a context
that can be understood within the framework of the wider world. So it becomes necessary
to use information that describes things outside the enterprise that can never be
changed by the transactions that the enterprise processes.
- Type codes, status codes, and role codes. These reference data tables constrain the design of a database and play a significant part in the business rule logic of any application. An example of a type code is shown in Figure 1, where the Customer Type table contains two records: one for "Institutional Customer" and one for "Individual Customer." It controls the subtypes of the Customer table, which consist of Institutional Customer and Individual Customer. Status codes similarly control entity life histories, and role codes control relationships of entities. This category of reference data is quite close to meta data, has values that are known when a database is designed, and is never updated by users.
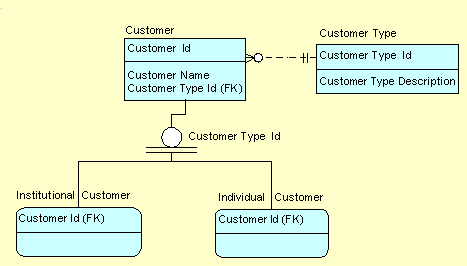
Figure 1: Customer Type -- A Typical Type Code
- Classification schemes. Any information in a database can be classified
in an infinite number of ways, although it is common for an enterprise to use just
a few schemes, e.g., Industry Classification. However, external organizations (particularly
regulatory authorities) may force the enterprise to report its information according
to additional classifications, e.g., based on environmental impact, energy consumption,
etc.
- Constant Values. The reference data we have discussed so far describes entities -- be they external things, design elements, or ideas. However, additional non-key reference data may be used by the enterprise. Tax rates are a good example. They are set by a particular jurisdiction and must be used by the enterprise. These constant values are nearly always non-key attributes of reference data tables
Reference Data -- Values with Meaning
Although reference data is quite diverse, it has some unique properties that give it cohesion as a distinct layer of data in an enterprise's information architecture. Perhaps the most important of these properties is that reference data values can have definitions. For example, a credit card issuer may categorize accounts in the way shown in Table 1.
|
Code |
Description | Definition |
|
A |
Highly Valued | Account holder has gross income of over $100,000 and has had an account with us for at least 24 months |
|
B |
Valued | Account holder has gross income of over $75,000 and has had an account with us for at least 12 months |
|
C |
Preferred | Account holder has gross income of over $50,000 and has had an account with us for at least 12 months with no late payments |
|
D |
Regular | Account holder is new or has had an account for less than 12 months |
Each primary key value in the Account Value Ranking table has a definition. Other kinds of data values in a database do not share this characteristic, e.g., the attribute Customer Id may have a definition, but not the individual value "12345" of Customer Id. Similarly, Order Id "88888," which is probably just a sequence number anyway, has no semantic difference to Order Id "77777" or Order Id "99999."
It is not only in reference data tables that are used to classify other data that definitions of values are important. They occur in the kinds of reference data that describe things that lie outside of the enterprise. For instance in Enterprise A "China" may be considered to include "Hong Kong," whereas in Enterprise B "China" may be defined as not including Hong Kong, and Hong Kong may appear as an additional record in their Country table. Status codes, type codes, and role codes also have values that have different definitions.
Rules to Create Reference Data Values
The definitions of the reference data tables that are classification schemes can themselves become business rules that are used to update transaction records with the appropriate value from the classification scheme. For instance, a particular account may meet the definition in Table 1 for being classified as "Preferred."
However, it must be remembered that classification schemes represent attributes that exist in human minds and are not intrinsic attributes of the entities being classified. For instance, we classify a lion as a mammal, based on the fact that it has hair, has sweat glands, and suckles its young. The term "mammal" exists only in human minds and is based on certain characteristics. Since these characteristics can be found in a lion, it is considered to be a mammal. The same is true of the credit card accounts in Table 1 -- they have characteristics that enable them to be classified according to the Account Value Ranking classification scheme.
What is vitally important to consider in constructing business rules to classify things is that the definitions identify characteristics that correspond directly to attributes of the entity being classified. These attributes must be present as columns in the implemented database. For example, the database upon which the classification scheme shown in Table 1 is constructed must contain accurate values (or contain accurate values that permit derivation) for:
- The account holder's annual gross income,
- The longest period of time for which any of the account holder's accounts have been open, and
- The total number of late payments on all of the account holder's accounts.
Unfortunately, definitions may sometimes be imprecise, and databases may not capture all the characteristics required by the definitions. When this occurs it is not possible to build automated business rules to classify other data. Human intervention is then necessary. For instance, to assign the correct SIC Code to a company may require an understanding of the company, some judgment, and perhaps a knowledge of how SIC Codes were assigned previously by the enterprise -- all of which adds up to a human operator making the decision.
Using Reference Data Values
Business rules that are built to assign reference data values to transaction data are vastly outnumbered by business rules that utilize reference data values directly within their logic. Why is this?
The answer comes from the fact that there is a great need to differentiate between different instances of an entity (i.e., different records in a table) that is not fulfilled by formal subtyping of entities. For instance, the subtyping shown in Figure 1 may be true, but we may need to deal with customers in many different ways other than the way they are subtyped.
It is reference data that allows us to build multiple independent sets of customers and then apply business rules that are specific to each set. For instance there may be specific business rules that have to be applied to:
- Customers living in the state where our enterprise is domiciled.
- Customers resident outside the USA.
- Institutional customers with the same SIC code as our enterprise.
- Customers classified as being in severe default.
- Customers classified as being high risk.
In all of these business rules, actual data values will probably appear in the business rule and these data values will be reference data. Here is an example from a program used by a US brokerage for allowing existing customers to open a margin account online, in both pseudocode and Visual Basic.
Pseudocode
*/ ?>
If Customer is resident outside of the USA then
Reject their application to open a margin account
End if
Visual Basic Code
*/ ?>
If Form.CTY_RESIDENCE_C <> "USA" Then
MsgBox "Only US residents can open a margin account.
Request to open a margin account is denied"
Exit Function
End if
This is not meant to endorse pseudocode or program logic for representing business rules, but merely to show how reference data values are commonly used in business rules to create special subsets of records within tables.
It is not simply individual business rules that may depend on a particular reference data value, but entire processes (sets of business rules) may operate on sets of records that are selected based on such a value. This is the great leverage that reference data provides -- the power to define business-meaningful subsets of records within a database table.
There is another feature of reference data that is also important for business rules. Since reference data connects the data of the enterprise to the world outside the enterprise it is a vehicle for implementing business rules that are forced upon the enterprise from the outside. For instance, the government may require that a brokerage cannot open any accounts for residents of certain countries.
Another example is tax rates supplied to an enterprise from national and local jurisdictions, which the enterprise must use to calculate taxes to be charged. This kind of data, which is not generated by the transactions of the enterprise itself, is held in reference data tables and often destined for use in business rules.
Reference Data Management
This brief review of what constitutes reference data and why it plays such a central role in business rules naturally leads to the question of how enterprises should manage it. Unfortunately, reference data is not recognized as a distinct layer of data with special management needs by many enterprises.
Worse than this, it is actually the object of a great deal of abuse. Programmers recognize the power of reference data and often implement it in program code -- inevitably calling it something like "record type." They build logic that is performed for Record Type "A" versus Record Type "B." Quite often many of these values do not exist in the corresponding reference data tables in the underlying database. Indeed, it is not uncommon to find columns in transaction tables that are evidently reference data and contain values important in program logic but for which no corresponding reference data table exists.
It is not only programmers who may be at fault. Users often come to understand the power of reference data as well. If reference data does exist in database tables and users have the means to update it, they may do so in order to "trick the system" into doing something special, such as avoiding the execution of certain business rules. They may even collude with programmers to add new values to tables that work within new program logic that the programmers add, even though these new values have no semantic relation to the other values in the reference data table.
These are just some of the problems that arise from the intimate connection between reference data and business rules. There are others, arising from (for example) different codes used to represent the same reference data in different databases and from a lack of understanding of the definitions underlying reference data values by systems development staff and users.
However, all of these problems have a root in the failure to manage reference data properly. When reference data is well managed there will be, at a minimum:
- A single accurate central copy of each reference data table within the enterprise, even if this data is redundantly implemented in different databases.
- Definitions for reference data values that are complete, correct, and easily accessible.
- A quality-control process that ensures that columns are not implemented in transaction data tables without corresponding reference data tables.
Even these rather limited goals cannot be attained without understanding one final fact about reference data. Since it describes things that the enterprise does not do business with, reference data typically has no "owners" within the business user community of an enterprise. There are very few enterprises that create or manage the actual things represented by Country, Currency, or Tax Rates, so no one within the enterprise is responsible for the data that describes them. Classification schemes that are defined outside of an enterprise (like SIC Codes) usually have no owners within an enterprise.
Even classification schemes defined within the enterprise tend to have been defined long ago by persons now unknown or by working groups that have long since disappeared. The reality is that the Data Administration function (which may be called by other names) must assume responsibility for the management of reference data and must be prepared to work directly with anyone who needs to use it -- be they developers, business users, or persons or organizations outside of the enterprise.
We have discussed the most fundamental properties of reference data that apply
to business rules. There are many other features of reference data that may also
need to be taken into account when implementing a business rules strategy. However,
what is vital for such a strategy is to recognize reference data as a distinct layer
of data in an enterprise's architecture that interacts with business rules in a special
way -- and has its own unique management needs.
# # #
Standard citation for this article:
About our Contributor:










Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.