The History of Modeling Decisions using Tables (Part 2)

In Part 1 an overview was given of early developments and fundamentals of tabular decision modeling, and of the conversion and algorithms era, building up to the 1982 Report of the CODASYL Decision Table Task Group: A Modern Appraisal of Decision Tables.[1] It is worthwhile to have a deeper look into this report (Figure 1) defining so many of the fundamental concepts, best practices, notation, kinds of tables, development methods, definitions, structures, application areas, etc.
Figure 1. The 1982 Report of the CODASYL Decision Table Task Group
The Decision Table Task Group was initiated in 1973 by CODASYL's System Committee. CODASYL (Conference on Data Systems Languages) is mostly known for its work on the development of the COBOL language and its activities in standardizing database interfaces (the CODASYL Data Model), but it also worked on a wide range of other topics. The Decision Table Task Group was chaired by Jonas Rabin from 1973-1975, by Paul Jorgensen from 1975-1978, and by Nick Marselos from 1978 until publication of the report.[2]
1. Basic concepts
A decision table is a tabular representation used to describe and analyze decision situations, where the value of a number of conditions determines the value of a set of actions.
The tabular representation of the decision situation is characterized by the separation between conditions and actions, on one hand, and between subjects and entries (condition or action values), on the other. The decision table thus consists of four elements: condition stub, action stub, condition entries, and action entries. Every table column (or row) indicates the action value(s) for a specific combination of condition values.
1.1 Definition
A decision table is a tabular representation of a decision problem. A decision table can be defined as a triple D = (C,A,R) where C is a set of conditions, A is a set of actions, and R is a set of rules, i.e., R is a relation that maps C into A so that A=R(C).
The condition set
- C is a set of conditions C(1),C(2),C(3),… relevant to the decision. Each condition C(i) consists of a condition subject CS(i) and a set of condition alternatives [CA(i,1), CA(i,2), …]. In the first decision tables (called limited entry decision tables) the set of alternatives was limited to Yes/No, but soon other alternatives were allowed, e.g., a range of values for Age: <20, 20-60 (both included), >60.
The action set
- A is a set of actions A(1),A(2),A(3),…. Each action A(i) consists of an action subject AS(i) and a set of action alternatives [AA(i,1), AA(i,2), …]. Sometimes the alternatives are limited to X and — (to save space), but any action alternatives (e.g., numeric values) are allowed. Depending on the purpose of the decision table, there can be one action with multiple alternatives only (e.g., in a classification decision), one limited true/false action only (e.g., in an eligibility decision), or multiple actions.
The relation
- R is a relationship that maps points of the condition space CS (Cartesian product of C) into points of the action space AS (Cartesian product of A). The condition space is the set of all combinations of condition alternatives, whereas the action space holds all combinations of action alternatives. The relation R consists of a series of rules, each of which associates a point in CS with a point in AS.
1.2 An example
Age
under 20
under 20
20-60
20-60
over 60
over 60
Sex
male
female
male
female
male
female
Customer
Type1
1
2
3
4
4
Figure 2. Expanded decision table
The table in Figure 2 shows all distinct combinations of the conditions Age and Sex and assigns them to CustomerType. The table is complete (if sex has only two distinct alternatives) and consistent (rules do not overlap). It is in expanded (canonical) form: every rule is a conjunction of single condition alternatives for every condition. Because some rules (i.e., columns) lead to the same outcome for every alternative of a specific condition (e.g., male or female in the last two rules), the expanded table can be represented more compact, without loss of meaning, as a contracted table (Figure 3).
Age
under 20
20-60
over 60
Sex
—
male
female
—
Customer
Type1
2
3
4
Figure 3. Contracted decision table
1.3 Tabular representation
The table is represented in a horizontal or vertical format (rules in rows or columns), as shown in this excerpt from the report (pages 3-4):

Figure 4. Tabular representation in rows or columns

1.4 Completeness and consistency
The relation R is said to be a function from CS to AS if
- The domain of R is CS, i.e., every point c in CS has an image R(c)=a in A.
- The image of c under R is unique.
These requirements can be restated in terms of the decision table representation. First, the table must be complete, i.e., have a rule for every combination of condition alternatives. And it must be consistent, i.e., the rules must not overlap (they must be pairwise mutually exclusive).
From a semantic point of view, this also implies that each condition must be complete and consistent relative to the universe (at least one and only one condition alternative should be present for each possible value of its subject).
1.5 Entry types
Historically, limited entry types have been:
- For conditions:
Y Yes (True)
N No (False)
— Irrelevant (The rule applies to any alternative of this subject.)
- For actions:
X Execute (Do the action specified by the subject.)
— Do not do the action specified by the subject.
By the time of the CODASYL report, limited entry types were almost history, and conditions and actions could take on any of an extended range of alternatives (value ranges, lists, etc.).
Dependencies
It is, however, interesting to observe some other symbols that have been used in decision table notation but are often forgotten. These notations, of course, originate from the use of multiple Y/N conditions instead of value ranges for one condition, which leads to cumbersome logical implications. But they relate to a much more important topic: dependencies between condition alternatives!
Additional symbols are:
Y! True by implication
N! False by implication
# Undefined (do not test, cannot occur)
i Impossible column
Impossible rules could be removed from the table, although they are usually kept for the sake of completeness. Care must be taken, however, not to remove rules that should never happen, because that is different from will never happen. These notations were mainly used in limited entry tables, in order to express some logical consequences.
Allowing ranges of values instead of just Y/N largely diminished the need for these logical consequences, for example:
X < 10
Y
Y
N
N!
X < 30
Y!
N
Y
N
Action
1
i
2
3
is replaced by:
X
<10
In [10,30]
>=30
Action
1
2
3
Figure 5. Simplifying limited entry conditions
This is a good case against using only Y/N entries for ranges of values. However, it also illustrates the concept of conditional dependencies — in this case, only logical dependencies — but it could be any kind of business rule! Be careful not to hide (or even neglect) the business rule but (instead) express it explicitly.
2. Types of decision tables
The most important question in describing types of decision tables is the question of overlapping columns.
In a pure single hit table, the rules in the table are mutually exclusive. The table is constructed in such a way that any combination of condition alternatives matches exactly one column/row. This makes an unambiguous decision possible and guarantees that all cases are handled by the table. That is easy for validation purposes.
Single hit tables occur in expanded or contracted form. In the expanded decision table, all combinations of condition states are explicitly enumerated, while in the contracted decision table, adjacent columns or groups of columns that only differ in the value for one condition and that result in the same action configuration are joined, thereby minimizing the number of columns. When all alternatives of a condition can be joined, the entry '—' (irrelevant) appears in the table. If all entries for a condition are '—' (or any of the derived implications indicated with '!'), the condition carries no relevant entries and is therefore redundant. It can simply be removed because the result does not depend on this condition.
Tables with overlapping columns are more difficult to validate. Because the columns of the table are not mutually exclusive, there is at least one combination of condition alternatives that matches two columns.
If the overlapping columns produce the same result, the table can still be called consistent, but there is some form of redundancy. This is not an immediate problem, but as with all redundancy, it might introduce inconsistency after future updates (lack of proper normalization). Figure 6 gives an example: the case (Phone,Non-US,Retailer) is present in 3 overlapping columns.
Type Of Order
Web
Phone
—
—
Customer Location
US
—
non-US
—
Type Of Customer
Wholesaler
—
—
Retailer
Special Discount
10%
Not
ApplicableNot
ApplicableNot
ApplicableFigure 6. A table showing redundancy
If the overlapping columns produce different and incompatible results (e.g., assigning two different classification results), the first hit convention is often used to enforce consistency. This means that the rules of the table have to be scanned one by one (usually from left to right, or top to bottom) until the first applicable decision rule is found. Sequence of the rules is involved now, and the table can hardly be called declarative! Only the first applicable rule will be considered to determine the action set and no further processing of the table occurs. Although the execution of the table is still consistent, validation in the modeling phase is very difficult. The table is often organized in such a way that exceptions are specified first, followed by more general rules. These tables also often contain a final ELSE rule to catch all remaining combinations. This means that they are complete by definition, but it is hard to determine if all intended relevant condition combinations are really present. The report explicitly recommends not to hide combinations in the ELSE rule.
Figure 7 is an example of a first hit decision table. The case (Y,N,Y) is overlapping, inconsistent, and resolved by the first hit convention. The cases (Y,N,N) and (N,N,N) are missing.
A=1
Y
Y
—
N
B>5
Y
N
N
Y
C=10
—
Y
Y
—
Result
accepted
accepted
refused
refused
Figure 7. A first hit decision table
A specific class of tables with potentially overlapping columns are called multiple hit tables (not to be confused with the first hit convention). This is considered an alternative interpretation for inconsistent tables because one can imagine applications in which it is desirable to have more than one rule apply to a specific case. Every rule appropriate to a case will be executed (and the results will be added, listed, or whatever is appropriate in the given context). The table is often organized in such a way that general rules are specified first, followed by more specific rules. A scoring table in a credit scoring context is a good example of a multiple hit table.
A multiple hit table is actually a series of single hit tables and can be reworked into that series. Why then would we ever incorporate several tables into one multiple hit table? Because a number of conditions or actions are shared and the table may produce an interesting or compact overview of the entire decision. However, when no conditions or actions are shared, the table is just a collection of rules and can better be split into independent single hit tables.
An overview
A classification of different types of decision tables can be found in the table shown in Figure 8.
Table contains exclusive rules only?
Y
N (some are overlapping)
Action values of overlapping rules are the same?
—
Y
N
Action values of overlapping rules are compatible?
—
—
N (conflict)
Y
Type of table
Single hit
Still consistent (but with redundancy)
Contradiction avoided by first hit convention
Multiple hit
Figure 8. A decision table of decision tables
3. Systems of decision tables
Most decision problems are too large to fit into one decision table and are therefore divided into problem segments which are then analyzed separately.
A decision table invokes another table by referring it. There are two forms:
- Tables invoked by conditions
Sometimes it is convenient to have a condition in one table invoke another table (the subtable) and to have the subtable return a value that is needed by the invoking condition. This, of course, models decisions using criteria that are decided in lower-level decision tables.
- Tables invoked by actions
A specific subset of decision logic (conditions, actions, and rules) can be grouped into a separate table and called from the actions of another table as a means to isolate (modularize) some decision logic.
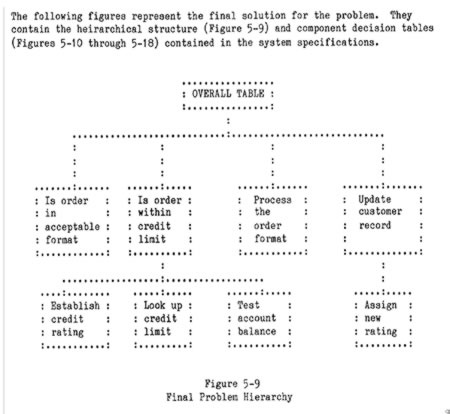
Chapter 5 of the CODASYL report contains an elaborate example of a problem hierarchy with multiple subtables, as follows:
The concepts of a condition subtable and an action subtable are shown in the following figure:

Linkages between tables could be eliminated by replacing each reference by the invoked table itself (called 'expansion'), but this process is usually not desirable because it introduces intermixed conditions and actions, redundancy, complexity, etc.
The opposite of expansion is 'factoring'. One factors a decision table by making selected segments separate tables that are invoked from the original table. The selected segments must be proper subtables of the original table (i.e., corresponding to a semantic decomposition, see pp. 3-13 of the report).
4. Conversion algorithms
Chapter 4 of the report is an elaborate description of implementation and execution techniques. As this is oriented toward tool builders, it is outside the scope of this article.
5. Development methodology
In Chapter 5 of the report, modeling and development methods are described extensively. This is the longest chapter, and it describes, among other topics:
- The role of decision tables in the systems life cycle
- Criteria for good tables and design guidelines
- Table development methods
- Problem structuring methods using table systems
- Implementation guidelines
- Maintenance and extension
The purpose of the chapter is to define various methods and techniques for using decision tables, both to develop system products and for modeling uses of decision tables.
5.1 Criteria for good decision tables
For the orderly and effective use of decision tables, a number of criteria and guidelines are introduced. There are at least five global recommendations, with different subitems:
- The importance of completeness
- Optimal table size, readability, and factoring
- Dealing with relations between conditions
- The need for consistency
- Format and representation
5.2 Table development methods
Composing decision tables can be done more effectively by using appropriate techniques. This will be elaborated in Part 3 of this series.
6. Education, examples, glossary and annotated bibliography
The report further contains a wealth of examples and educational topics, and concludes with a very complete overview of decision table literature up to 1982, with a summary of 500+ decision table publications.
… continued in Part 3References
[1] Codasyl [82], "A Modern Appraisal of Decision Tables," Report of The Decision Table Task Group, ACM, New York, 322 pp., 1982. ![]()
[2] The report can be downloaded from: http://www.econ.kuleuven.be/prologa/publications.htm (read the reproducing policy). Of course, this is a 1982 report reflecting the state of the art at that time. Download an updated version of chapters 1-2 from: http://henry.beitz.org/pdfs/DTTG1982/report-1-2.pdf. More about the evolution since 1982 in the parts to come in this series. ![]()
# # #
Standard citation for this article:
About our Contributor:










Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.
How to Define Business Terms in Plain English: A Primer
How to Use DecisionSpeak™ and Question Charts (Q-Charts™)
Decision Tables - A Primer: How to Use TableSpeak™
Tabulation of Lists in RuleSpeak®: A Primer - Using "The Following" Clause
Business Agility Manifesto
Business Rules Manifesto
Business Motivation Model
Decision Vocabulary
[Download]
[Download]
Semantics of Business Vocabulary and Business Rules