What Is AI?

In the time that browsing was called surfing and computers used floppies, I studied AI and had to explain what it was all the time. The answer I gave was different from the answer that the Gartner-hype-cycle-analyst would give today. Hence, there are multiple answers from different perspectives.
It's a tricky question.
My next column will therefore answer a question that is equally important: What AI is not?
But first let me give you some different perspectives to start off:
- For my mother, AI is still "something with computers" when asked what I do, and her friends are likely to be satisfied with that answer.
- For most people not familiar with the topic, AI is about mimicking human intelligence with a computer such that it's 'doing something really smart', like playing chess or forecasting — things that people generally believe to be difficult.
- For the Gartner analyst, it references a family of algorithms that use a lot of data, computer processing power, and relatively-simple algorithms to find patterns in that data, aka machine learning or deep learning.
- For the scientist, it references a research area of using computers to mimic human intelligence; it is related to understanding human intelligence but does not need to use the same (biological) methods.
When are we ready with AI?
The irony is that once AI mimics an intelligent task successfully, we often do not find it intelligent any more: The target of AI is a moving horizon. This has happened to tasks like:
- searching for similar or related documents
- finding the optimal plan or schedule
- finding the shortest route between multiple places (travelling salesman problem)
Since we relate the definition of AI to human intelligence, and there is no finite list of tasks that are considered to be intelligent,
AI will never be 'ready' or 'finished'.
We will instead continue to find better ways to use machines to do complex tasks that are otherwise considered intelligent when performed by humans. Computer programs may reach impressive performance on some of these tasks. AI may even outperform humans in some ways.
What kind of AI research is done?
The quest for ways to mimic human intelligence with machines will continue to be a research topic. AI research became a discipline after the Second World War. The topics that have been researched have changed over time and have involved different disciplines, such as:
- Logic and mathematics to create decision support systems
- Philosophy to understand the nature of conscience, ethics, and human beings
- Psychology to improve our understanding of how cognitive tasks may be performed (both by humans and machines)
- Sociology to understand human-machine interactions
- Language theory to understand how semantics can be captured and evolves
Computer science and computational theory are not on the list. While certainly related research areas, they do not get to the fundamentals of problems that AI considers.
The research, so far, has resulted in technology that we use daily. Many of us are not aware that we are using AI technology when searching the Internet, using our credit card, or chatting with a chatbot. AI technology is all around us.
The result of AI research is new technology.
The resulting technology is typically classified as one of two dimensions:
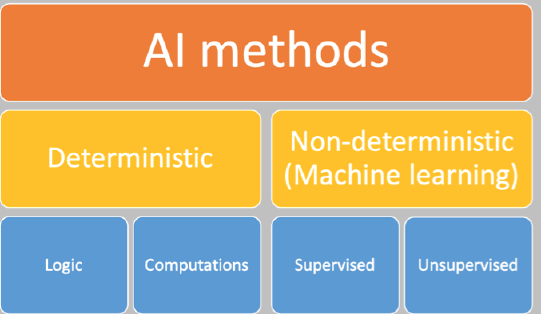
Deterministic AI methods …
… accomplish a task or generate an outcome in a way that is completely designed in advance. Given the same state or input, the method will always return the same result. The method typically uses explicit knowledge represented in a model based on logic or computations. A rule-based system is the most well-known example.
An important characteristic is that these systems do not produce a result for situations that they are not designed for. Another way they are often framed is being unable to deal with uncertainty. This is partly true. If we classify uncertainty in a quantifiable way (for example, as a number between 1 and 10), we can make a deterministic system that takes this uncertainty into account (a Bayesian network).
There are many problems that are non-deterministic by nature but can be well-supported using deterministic methods. Some examples include:
- Fraud detection. Although detecting fraud is a task that is uncertain by nature (we do not know what methods the fraudulent party is using in advance), most fraud detection systems do use rules to detect potential fraudulent cases.
- Traffic management. Although it is highly uncertain how road users react to traffic congestion and therefore how congestion problems evolve, we do use rules and scenarios to minimise the consequences of traffic congestion for road users.
But luckily for deterministic AI, there are also tasks that need to be deterministic by design. For example:
- Tax deduction calculations. The tax code uses rules that ensure taxpayers are all treated in exactly the same way.
- Claim handling. Insurance companies use rule-based software to determine if an insurance claim is eligible based on the conditions stated in the policy.
Non-deterministic or machine learning methods …
… generate results for a task based on patterns that are found using advanced statistics and (big) data. The model is created using a generic method, and the resulting input-output relationship is implicit. Typically, these methods generate multiple outcomes for the same state or input.
The result could be incorrect. Outcomes are, therefore, rated based on measures such as accuracy, generality, and precision. Some results are rated better than other results and, depending on the problem domain, we may be satisfied with anything better than random accuracy or an accuracy level close to 100%.
Within this dimension, an important distinction is made between supervised learning methods and unsupervised learning methods.
In supervised learning there is a 'teacher' that knows the right answers in advance; the teacher will tell the system when a generated outcome is 'right' or 'how right it is'. Some machine learning algorithms will use this information to guide the learning process in a certain direction. However, sometimes this may drive the results in the wrong direction. When the problem space is non-linear, these algorithms may not always find the most optimal solution. In fact, we can't know that there actually is an 'optimal' solution. So, to improve our chances of finding the optimal solution, we just repeat the process many times, using large amounts of processing power. And we also add in random variations to the algorithm because this random variation may hit a 'lucky shot' that finds a more optimal solution. This is not magic — simply a matter of try, try, and try again (like a toddler solving their first puzzle).
In unsupervised learning there is no 'teacher' and we do not know what the right results are in advance. Algorithms may be used for these tasks and would be looking for similarity in datasets and, when presented with some input, will present similar results.
Because the non-deterministic AI methods are prevalent in the most recent AI hype, let me explain a couple of buzzwords within this context:
- Neural networks are non-deterministic AI methods and may be used for both supervised and unsupervised learning, and
- Deep learning combines multiple neural networks (sequentially) to solve a task.
How does deterministic vs. non-deterministic AI relate to XAI?
In my previous column we concluded that "all decision support systems should be able to justify their results with an explanation." Therefore, Explainable AI (XAI) is important, and the business has to invest in XAI.
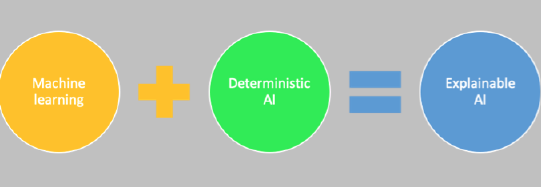
But the knowledge in the model generated by a deep learning algorithm is implicit. This is a major disadvantage because it becomes very difficult to explain what the model has learned or how the result is calculated. Deterministic AI methods do not have this disadvantage: For each result, a very precise recipe can be generated that tells exactly which rules are used, and in what order, to get to the result.
XAI brings both worlds together.
It is possible to train a model using deep learning methods and to use the resulting dataset to generate a deterministic decision tree with the same, or similar, accuracy as the trained model. The decision tree consists of rules that may be used to provide explanations.
Is it that simple? Yes and no. Sometimes we may not have human concepts or words for the combinations that the deep learning algorithm uses. Here the analysts and human experts come back into the game. Assume that these concepts are important to solve an issue; then why don't we know about them? And what is the value if we can't explain them?
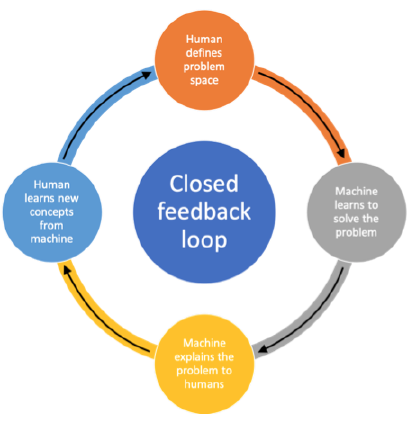
There is an opportunity to close the feedback loop between the human who defines the problem and solution space, the machine that learns to solve the problem and provides an explanation, and the human who learns new concepts based on the explanation.
Remember: To select the best way to use an intelligent machine you need to know what it learned and what it can and cannot do.
Please follow me to receive an update on the next column in this series on what AI is not.
About this series: I have been fighting for years for transparent decisions — decisions that you can explain, that you can relate to policy, where you can demonstrate that they comply with policy and legislation, and where it is clear that they are part of a flexible PDCA process in an agile environment. Making decisions based on rules is easy to do, although we don't always do it well. Now that the AI hype is at its peak, I have a feeling that I can start all over again. The battle doesn't get any easier because the AI world loves to envelop itself in complexity that takes on mythical forms. It's not complex — you and I can make a difference! Because it's close to my heart, I will continue to write.
This is the second column in a series of 10 — to help you and me make sense of it by sharing my ideas, questions, answers, and inspiration. Will you share with me too?
I would really appreciate your feedback.
Let me know if you liked this column by sharing it in your network.
# # #
Standard citation for this article:
About our Contributor:

")







Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.
How to Define Business Terms in Plain English: A Primer
How to Use DecisionSpeak™ and Question Charts (Q-Charts™)
Decision Tables - A Primer: How to Use TableSpeak™
Tabulation of Lists in RuleSpeak®: A Primer - Using "The Following" Clause
Business Agility Manifesto
Business Rules Manifesto
Business Motivation Model
Decision Vocabulary
[Download]
[Download]
Semantics of Business Vocabulary and Business Rules