The Conflicting Senses of the Term 'Data Model'

Excerpted from Models, Metaphor and Meaning: How Models use Metaphors to Convey Meaning.
In order to see how confused we are about the term 'data model', we need only look at hurricane weather forecasting.
During hurricane season we are usually confronted with different forecast models that predict different paths for the same hurricane. There are two primary weather forecasting models, with many variations. These data models combine a set of equations that relate the weather sensor input at various locations and make predictions on the path of the storm. The weather model depends greatly upon data assimilation: how the data is populated. The model depends on how the sensors are spaced out geographically and the latency of the updates. All of these variables inform how accurately the model predicts the weather.
When the weatherman says, "The European model predicts this path, but the American model predicts this other path", what they're referring to is a combination of different algorithms working on different databases fed data values by overlapping terrestrial and satellite sensors.
In the IT world, the term 'data model' refers to either the conceptual, logical, or physical models — or any combination of the three. The data model does NOT usually include the populated database with the data values or rows. And it certainly does NOT include the application logic or algorithmic code that produces information from the populated database. This is very different from the way data scientists and the public conflate the terms 'data model' and 'model of the data'.
A typical IT data model is the entity relationship diagram (ERD). This one uses Information Engineering (IE) notation.
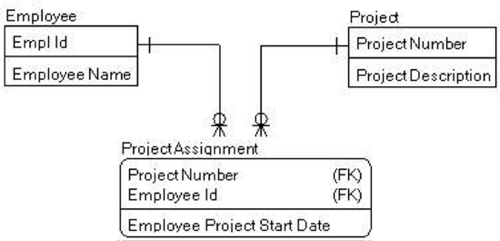
David Hay has been quick to point out that the entities in an ERD are really entity types. They are equivalent to the classes of an Object Oriented (OO) class diagram. And a data model should really be called a meta data model. The meta data model forms the schema or ontology describing the things in that domain. Unfortunately, it's common IT practice to shorten meta data model to just data model.
Model of the Data vs. Data Model
In the introduction to, The Experimental Side of Modeling, Peschard and van Fraassen make the important distinction between the model and the data.[1]
Measurement is the means through which data, and subsequently a data model, are obtained. To understand what sort of data model can be obtained we need to understand what sort of data can be obtained.
What these authors are referring to as the "subsequent data model" is the final published form of the experimental observations, as defined by the metadata and the data values. This quote shows that data scientists presume that the data model is subsequent to or derived from the data. This is exactly opposite to how IT designs the data model first, then populates the database afterward.
The reason IT limits the data model to mean just the entity types and relationships is due to both timing and division of labor. The data model is a separate deliverable. In the lifecycle of a typical software development project, the data model is started in the requirements phase and delivered in the design phase. The skills required to do data modeling are different from the analysis skills of the business analyst or the coding skills of the DBA or software developer.
The data modeler/data architect develops the conceptual and logical data models by analyzing the meanings of concepts to resolve homonyms and synonyms so that the resulting database will express the information correctly. The data modeler can then generate the first-cut physical data model from the modeling tool. The first-cut physical model is handed off to the DBA. The DBA enhances the physical data model by adding detailed storage specifications to generate the physical database structures. All of this occurs before any data can be recorded in the database. The data model is prior to the populated database.
Another more subtle reason to differentiate the meta data model from the model of data values is because one can draw radically different conclusions from a set of data values depending on how that data is organized, related, and subsetted. And if it's left up to the application to decide how to relate the data, they can probably find relationships that may be random or accidental. Perhaps these accidental relationships depend on misunderstandings of meta model synonyms or homonyms.
It might be suggested that we limit the term 'data model' to mean only the meta model, the abstract data blueprints PRIOR to being populated with data values. But this would be going against common vernacular (e.g., weather models). It's never a good idea to try to proscribe how people should talk. Instead, maybe we can learn to look at data models as visual metaphors that express their meaning in figurative language.
The purpose of the data model is not just to show a graphical image of the relational data tables. The ultimate purpose is to map the business requirements onto the physical database so the application system can generate meaningful information. The logical data model must bear a likeness to the cognitive models in the minds of the business people who analyze various states of the business environment. Data models are visual metaphors designed for the specific purpose of developing databases for information systems. The visual image of the boxes and lines is not as important as the mental mapping between the requirements and the functioning database in the information system.
References
[1] Isabelle F. Peschard and Bas C. van Fraassen (eds.), The Experimental Side of Modeling, University of Minnesota Press (2018), 325pp.
# # #
Standard citation for this article:
About our Contributor:










Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.