The History of Modeling Decisions using Tables (Part 3)

1. Introduction
In Part 1, an overview was given of early developments and fundamentals of tabular decision modeling, and in Part 2, the 1982 Report of the CODASYL Decision Table Task Group: A Modern Appraisal of Decision Tables[1] was described in more detail.
Although decision tables still look almost the same as in these days, some profound changes can be noted since the eighties. Most of these developments were already started in the CODASYL report and have been elaborated in the following two decades:
- The application area has extended from programming towards various other domains with logical complexity. This extension has directed research efforts from the efficient implementation of the tables towards the modeling process. The enlargement of the application field is illustrated through the use of decision tables in knowledge engineering and validation, conditional logic representation, rules and regulations, standard operating procedures, etc.
- The objective has changed: the emphasis has moved towards the power of decision tables to represent complex decision situations in a simple manner, easy to check for consistency, completeness, and correctness. Because of this quality requirement, the representation and structure of decision tables have received considerable attention after 1982. The variety of extensions and interpretations of the decision table formalism were reduced and some standard representations and refinements were proposed in order to fully enjoy the advantages of decision table systems.
This article summarizes guidelines, constraints, and best practices when modeling decision tables, based on extensive use of the decision table technique in a large number of environments and application areas. The requirements on structure, form, and layout emanate from the need to use decision table models as a well-structured technique across various application areas.
2. Refining and Standardizing Decision Table Modeling
In the past, many variations of the decision table concept have been used, without making a proper distinction between them, thus leading to confusion and reduction of the applicability of the formalism. In order to deal with any confusion, a number of principles and constraints to the decision table formalism were proposed in the eighties and nineties. All these guidelines can be found in earlier publications, e.g.: Vanthienen J, Dries E, Developments in decision tables: evolution, applications and a proposed standard, 1992.[3] This section summarizes the major criteria and guidelines for the orderly and effective use of (systems of) decision tables (Table 1).
- Structure and content
- Basic structure and the importance of completeness and consistency
- Extended entry tables (multi-valued conditions)
- Exclusivity and completeness of the condition entries (domain partitioning)
- Exclusivity and completeness of the rules (types of decision tables)
- Types of actions
- Form, conciseness, and readability
- Horizontal or vertical format
- The order of the rules is irrelevant, but not for humans
- Group-oriented contraction
- The order of the conditions is irrelevant, except for display size
- Row order optimization
- Tree notation
- Block-oriented notation
- Representing relations between conditions (indicating impossible rules)
- Factoring and normalization
- Subtables
- Intertabular verification
- Purpose and pragmatics
- Decision logic and structure
Table 1. Criteria for good decision table models
A. Structure and content
1. Basic structure and the importance of completeness and consistency
Decision tables represent rules about related conditions and actions. The purpose of the decision table is that a given combination of condition entries leads to a specific set of actions. By definition of the decision table, all elements in one rule (condition and action combinations) are implicitly connected with AND; all rules are connected with OR.
There should be no missing combinations. But completeness can be obtained in two ways: either by design or by providing a remainder column that catches all missing rules. The latter solution is complete by definition, and even compact, but a little less elegant.
The same holds for consistency: a specific combination of condition entries should not correspond to more than one column/row. This can also be obtained in two ways: either by design or by providing a mechanism that resolves overlapping combinations (e.g., the first-hit convention to obtain single-hit tables). Although both designs will produce a consistent table, the latter is more difficult to verify by humans and requires tool support to ensure consistency.[4]
It is, of course, rather easy to pronounce, as some methods do, that rules should be complete, consistent, independent, etc. The real issue is: how do you check it, make it possible, and even better, guarantee that the modeling criteria are obtained automatically?
2. Extended entry tables (multi-valued conditions)
Although historically only limited entry condition types (with Yes/No) have been used, conditions now commonly take on multiple entries (enumerations, intervals, but also Y/N). Limited entry has some advantages in occupying less space per column, but it leads to cumbersome and undesirable logical dependencies between conditions and provides less overview. So even though all extended entry tables can be converted to limited entry tables, extended entry tables offer considerable modeling advantages.
3. Exclusivity and completeness of the condition entries (domain partitioning)
When conditions have multiple entries they have to obey the requirement of completeness and exclusivity with respect to the entries. The entries should not overlap, and together cover the entire domain of the condition (partitioning). This means that each possible value of a condition has to be included in one and only one entry. A condition 'Age' (for example) should not contain both expressions 'Age <= 40' and 'Age >= 40', and should include all possible ages. This requirement is necessary to obtain a complete and exclusive decision table.
4. Exclusivity and completeness of the rules (types of decision tables)
Good decision tables have to meet the demand of completeness and exclusivity with respect to the rules. Each combination of condition entries should lead to one and only one rule (row or column). Otherwise the table is not complete or can produce inconsistent results. Because decision tables are relations, this is simply the requirement of normalization.[7]
The most important question in describing types of decision tables is the question of overlapping columns. Tables with overlapping columns, even if these columns produce the same result, are more difficult to validate (certainly for humans). Because the columns of the table are not mutually exclusive, there is at least one combination of condition entries that matches two columns.
We can distinguish two major types of tables: tables resulting in only one action configuration (single-hit) and tables resulting in a set of action configurations that are added or combined (multiple-hit).
1) Single-hit tables aim to produce one (and only one) action configuration for each condition combination. There is however a difference in how the rules are represented, because overlapping rules may create redundancy, inconsistency or confusion. The following three types of single-hit tables should be distinguished:
a. (Overlapping, any hit): If overlapping rules/columns are present and the overlapping rules produce the same result, the table can still be called consistent, but there is some form of redundancy. This is not an immediate problem, but as with all redundancy, it might introduce inconsistency after future updates (lack of proper normalization). This requires a little verification. The following figure shows a table with some overlapping columns (the last three columns) that have the same result.
Figure 2. Overlapping rules, showing redundancy
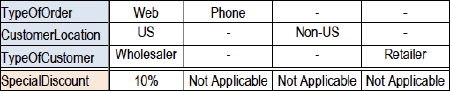
Because of the overlapping columns it is also harder to verify if the table is complete. This will require some calculations of all condition combinations covered.
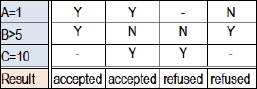
b. (Exclusive): In a pure single hit table, all rules in the table are mutually exclusive, non-overlapping. The table is constructed in such a way that any combination of condition entries matches only one (and exactly one) column/row. This makes verification straightforward, even unnecessary.
Figure 3. Exclusive rules
c. (Overlapping, first-hit): If the overlapping columns produce different and incompatible results (e.g., assigning two different classification results), the first hit convention is often used to obtain a single-hit table and maintain consistency. This means that the rules of the table have to be scanned one by one until an applicable decision rule is found. Only this rule will be considered to determine the action set and no further processing of the table occurs (this is sequence dependent!). Although the execution of the table is still consistent (or, better, made consistent), verification in the modeling phase is more difficult for humans and requires tool support (in which case the table can be considered a viable intermediate specification device). The table is often organized in such a way that specific cases are specified first, followed by a more general final ELSE rule to catch all remaining combinations. The CODASYL report already recommended not to hide combinations in an ELSE rule.
Figure 4. First-hit table
Here is another example, which clearly shows overlapping, inconsistent, and incomplete rules.
Figure 5. First-hit table with incompleteness
Why is this distinction between non-overlapping and overlapping (first or any hit) tables important? Because modeling the correct decision logic is so important. And any way to support the verification process is welcome. Also, tooling will help a lot here.
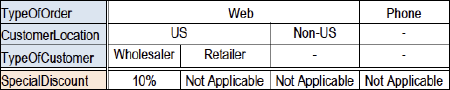
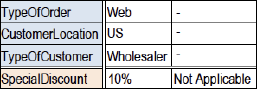
2) All hits: A specific class of tables with potentially overlapping columns are multiple hit tables (not to be confused with the first hit convention), in which it is desirable to have more than one rule apply to a specific case. Every rule appropriate to a case will be executed (and the results will be added, listed or whatever is appropriate in the given context). A scoring table in a credit scoring context is a good example of a multiple hit table.
An interesting form of a multiple-hit table is the so-called decision grid chart, a tabular representation of a set of decision rules, ordered by outcome. The decision grid chart primarily has a specification function while the single hit decision table offers more verification possibilities. This is the concept of the life cycle of the decision table.[2]
A multiple hit table is actually a series of single hit tables and can be reworked into that series by factoring and normalization.[8] But it might also be interesting to show all rules together in one (denormalized) table because a number of conditions or actions are shared and the table may produce an interesting or compact overview of the entire decision. If no conditions or actions are shared, the table is just a collection of rules and can better be normalized into independent single hit tables.[6]
Figure 6. A multiple-hit table
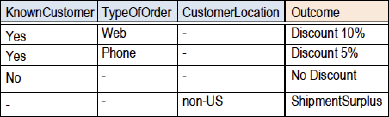
Figure 7. Factoring the multiple-hit table
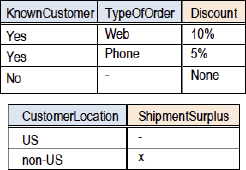
Figure 8. An overview in one single hit table (denormalization)
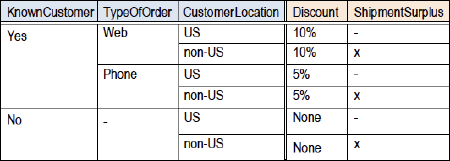
5. Types of actions
Decision tables can have multiple actions. If the purpose of the table is to assign an outcome to a (sub)decision, the main action will assign that outcome, e.g., true/false, classification results, values. There may also be additional outcomes, depending on the purpose of the table.
Actions can be written in shorthand notation (Eligibility: +,-) or in full (Eligible, Not eligible), depending on the number of values and the available space.
As indicated in Figures 7 and 8, there can be one major outcome for each table, or multiple outcomes can be shown, e.g., for verification purposes.
B. Form, conciseness, and readability
6. Horizontal or vertical format
Orientation is a matter of taste and space. In general, if the number of conditions and actions is rather low, a horizontal orientation (rules in rows) is possible. If the number of conditions is three or less, a square representation may be considered. If the number of conditions (and actions) is higher, the vertical orientation (rules in columns) will produce more overview.
7. The order of the rules is irrelevant, but not for humans
In case of single-hit tables, good decision tables contain exclusive rules (or in case of overlapping rules, at least rules with the same outcome). In multiple-hit tables, order should not matter. But that does not mean that the presentation order is irrelevant; it is easier for humans if condition entries are presented in a natural order (e.g., from low numbers to high numbers), or if the entries of the lowest conditions vary first. This also allows easy checking for completeness. So indeed, rule order doesn't matter, but gives extra value.
8. Group-oriented contraction
In the expanded decision table, all combinations of condition values are explicitly enumerated, while in the contracted decision table, adjacent columns or groups of columns that only differ in the entry for one condition and that contain the same action configuration are joined, thus reducing the number of columns. When all entries of a condition can be joined, the entry '-' (irrelevant) appears in the table. Contraction minimizes the number of columns for a given condition order.
If all entries for a condition are '-' throughout the entire table, the condition carries no relevant entries and is therefore redundant. It can simply be removed because the actions do not depend on this condition (normalization rule).
9. The order of the conditions is irrelevant, except for display size
Because condition entries are ANDed to form a rule, the order of the conditions in the table does not influence the meaning. However, because of the contraction mechanism, the place of conditions may influence the size of the contracted table, so reordering may make a difference, as indicated in the following example.
Figure 9. A simple table with 6 rules
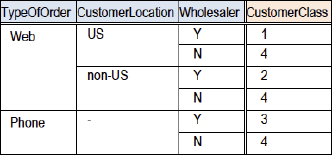
Figure 10. Reordering conditions produces only 4 rules
The display order of the conditions does not mean that conditions have to be tested in that order. The execution order of conditions in a decision table is an implementation issue, not a modeling issue.
10. Row order optimization
Row order optimization determines the condition order that results in the minimum number of (contracted) columns. In a decision table, the condition order is the same for all columns of the table, but a different condition order may produce a smaller table because of contraction. For a table with n conditions, this implies a choice between n! alternative condition orders.
11. Tree notation
When the rules are exclusive and ordered in such a way that the entries of the lowest conditions vary first, a natural tree structure appears. The condition combinations then appear from left to right in lexicographical order, each condition showing the relevant entries within the given entry of the higher condition. The decision table then corresponds to a tree where the same condition is always evaluated at a certain level of the tree, in contrast with a general tree where conditions can be enumerated in a different order in distinct branches of the tree.
Besides the fact that the tree structure principle eliminates "rule ambiguity" (more than 1 column satisfied), it provides an easy way for humans to consult the decision table (top-down) and to guarantee completeness. This principle eliminates the need to examine the rules one by one, from left to right, when making a decision.
12. Block-oriented notation
Emphasizing the tree notation, it is advantageous that each node (condition entry) of a path is represented only once in the table. Therefore, consecutive equal condition entries (repeating themselves on the same row) with the same value for the higher conditions are only displayed once. The following notation is therefore preferred.
Figure 11. Representing decision nodes only once
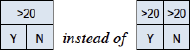
Furthermore, the visual interpretation of the tree principle means that a condition entry in the table (a "block") can never be enlarged by a following condition, but can only be split into other condition entries, depending on the relevant entries of this last condition (if there are any). Therefore each vertical line, once started, has to continue to the bottom of the table without interruption.
Figure 12. Keeping the tree notation

This representation makes the table easier to read and understand. In addition, by eliminating redundancy, it enhances compactness. Although it may sometimes save space to violate the tree-notation (if this causes no ambiguities) by combining adjacent equal entries with different parents starting from some condition (exactly as adjacent branches in a decision tree can be brought together again), this has a very unfavorable effect on readability.
13. Representing relations between conditions (indicating impossible rules)
Exceptionally, some condition combinations might be impossible because the entry of one condition may be implied by entries of earlier conditions (especially in limited-entry tables). This would imply relations between conditions within one table and they can be represented in different ways: by adding a special action, by deleting or marking the impossible column, or by contracting possible and impossible columns, with or without a special marking about the semantics of the contraction. Impossible rules could be removed, although they are usually kept for the sake of completeness. Care must be taken, however, not to remove rules that should never happen because that is different from will never happen.
If relations between conditions exist (other than the result of using limited-entry conditions), the rules of normalization[6] indicate that is a better option to split the table (factoring).
C. Factoring and normalization
14. Subtables
Decision problems are almost always too large to fit in one decision table and are divided into problem segments that are then analyzed separately. Also, relations between conditions (a set of conditions determining the value of another condition, called a subdecision) and other normalization rules lead to systems of decision tables.
Two types of subtables are possible: a condition subtable determines the value of a condition in another table and returns this value. This allows modeling decisions in layers of decisions and subdecisions. An action subtable further specifies the details of a certain action and then gives back control to the calling table.[8]
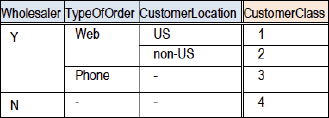
Here is an example of a condition subtable that determines the value of Customer.Type, a condition that is used in the top decision.
Figure 13. Decision structures
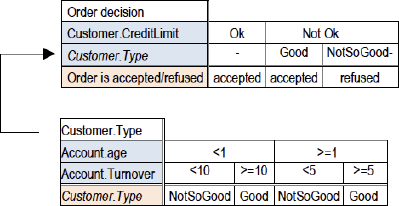
15. Intertabular verification
One of the major reasons for using decision tables is the fact that they can be checked rather easily for anomalies, or if the tables are well designed, as described in this article, anomalies can be avoided.
When decisions are represented in multiple tables, however, it is still possible that conditions in one table are related to decisions in another table. This may lead to complex intertabular anomalies. Intertabular verification is beyond the scope of this article, but more information can be found in [5].
D. Purpose and pragmatics
16. Decision logic and structure
Decision tables are the representation of a complex decision and should be confined to selection structures. They should therefore not include initialization or iteration facilities in the table itself. Features to deal with other than selection structures have caused a loss of simplicity and uniformity of the decision table technique in the past. These features can be realized using the proper surrounding constructs and should not be part of the tables.
In decision tables the separation between conditions and actions has to be clear or easy to reach. Mixing conditions and actions is not good practice. A fact type that is both outcome and condition in a decision obviously corresponds to a condition subtable.
The concise representation of the decision table appears to its full advantage when various rules of the decision table have conditions and actions in common. In that case, the application area of the resulting actions is represented in a clearly structured and compact way.
The appropriateness of the decision table technique depends on these three criteria. However, as can be seen from the historical evolution of decision table modeling, this does not imply that the application field is small or unimportant.
3. Conclusions
Over the years there has been a major change in research and application areas of decision tables. Current decision table models mainly benefit from the representational advantages of the technique. They improve the modeling and communication in various business domains because decision table models are precise, consistent, and understandable. In the past, different kinds of tables have been used, however, and not all of them offered these representational capabilities. Based on numerous experiences with decision tables, a refined decision table concept and a number of standards have been proposed, in order to allow a more powerful use of the technique.
References
[1] Codasyl, "A Modern Appraisal of Decision Tables," Report of The Decision Table Task Group, ACM, New York, 322 pp., 1982. ![]()
[2] Maes R., Van Dijk J. E. M., "On the Role of Ambiguity and Incompleteness in the Design of Decision Tables and Rule-Based Systems," The Computer Journal, 31(6), 481–489, 1988. ![]()
[3] Vanthienen J., Dries E., "Developments in decision tables: evolution, applications and a proposed standard," DTEW Research Report 9227, pp. 1–40, 1992. ![]()
[4] Vanthienen J., Mues C., Goedertier S., "Experiences with modeling and verification of regulations," Proceedings of the CAiSE'06 Workshop on Regulations Modeling and their Validation & Verification (REMO2V'06), pp. 793–800, 2006. ![]()
[5] Vanthienen J., Mues C., Wets G., Delaere K., "A tool-supported approach to inter-tabular verification," Expert systems with applications, Vol. 15, No. 3–4, pp. 277–285, 1998. ![]()
[6] Vanthienen J., Snoeck M., "Knowledge Factoring Using Normalization Theory," International Symposium on the Management of Industrial and Corporate Knowledge (ISMICK'93), Compiègne (FR), pp. 97–106, October 27–28, 1993. ![]()
[7] Vanthienen J., Wets G., "Integration of the decision table formalism with a relational database environment," Information Systems, Vol. 20, No. 7 (Nov.), pp. 595–616, 1995. ![]()
[8] Vanthienen J., Wijsen J., "On the Decomposition of Tabular Knowledge Systems," New Review of Applied Expert Systems, pp. 77–89, 1996. ![]()
# # #
Standard citation for this article:
About our Contributor:











Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.
How to Define Business Terms in Plain English: A Primer
How to Use DecisionSpeak™ and Question Charts (Q-Charts™)
Decision Tables - A Primer: How to Use TableSpeak™
Tabulation of Lists in RuleSpeak®: A Primer - Using "The Following" Clause
Business Agility Manifesto
Business Rules Manifesto
Business Motivation Model
Decision Vocabulary
[Download]
[Download]
Semantics of Business Vocabulary and Business Rules